Understanding Krawler
krawler is powered by Feathers and rely on two of its main abstractions: services and hooks. We assume you are familiar with this technology.
Main concepts
krawler manipulates three kind of entities:
- a store define where the extracted/processed data will reside,
- a task define what data to be extracted and how to query it,
- a job define what tasks to be run to fulfill a request (i.e. sequencing).
On top of this hooks provide a set of functions that can be typically run before/after a task/job such as a conversion after a download or task generation before a job run. More or less, this allows to create a processing pipeline.
Regarding the store management we rely on abstract-blob-store, which abstracts a lot of different storage backends (local file system, AWS S3, Google Drive, etc.), and is already used by feathers-blob.
Global overview
The following figure depicts the global architecture and all concepts at play:
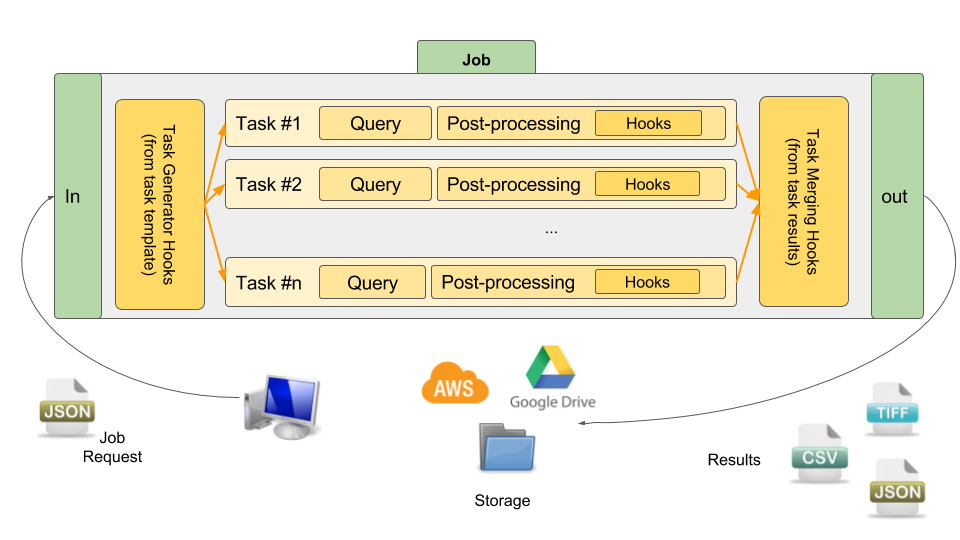
What is inside ?
krawler is possible and mainly powered by the following stack:
- Feathers
- Lodash A JavaScript utility library
- node-gdal the Node.js binding of GDAL / OGR used to process rasters and vectors
- js-yaml used to process YAML files
- xml2js used to process XML files
- json2csv used to process CSV files
- fast-csv used to stream CSV files
- abstract-blob-store used to abstract storage
- request used to manage HTTP requests
- node-postgres used to manage PostgreSQL database
- node-mongodb used to manage MongoDB database