Using the Kano API
Description
Kano exposes an API endpoint that can be used to query data stored in it's underlying MongoDB database. The API will return JSON documents when queried. The endpoint is located on $KANO_ROOT_URL/api/
What's available
This depends on which layers are declared in your Kano configuration. For each layer declaring a set of features services, the api will expose the service's data through an URL formed by the API endpoint slash the service name.
Example
If your Kano instance is exposed through https://kano.foo.xyz then the api is available on https://kano.foo.xyz/api. If for example you have the hubeau hydro layer enabled (which instanciate both a hubeau-hydro-stations and a hubeau-hydro-observations features services), then the api will expose it's data on https://kano.foo.xyz/api/hubeau-hydro-stations and https://kano.foo.xyz/api/hubeau-hydro-observations
Authentication
In order to access the API, clients must authenticate themselves. We use JWT tokens to authenticate access to Kano. Those can be added as an HTTP query parameter, using jwt=$your_token or can be passed through the Authorization HTTP header, using the Bearer scheme.
Generate a JWT token
Kano supports stateless tokens, i.e. tokens not associated to a user, either to access the backend API or to automatically login when using it through an iframe. To generate a token you can use https://jwt.io with your app secret and the default header:
{
"alg": "HS256",
"typ": "JWT"
}Your payload should at least look like this:
{
"name": "your token id",
"iss": "kalisio",
"aud": "your app domain"
}You can also add others token properties like an expiration date (exp).
TIP
In development mode aud=kalisio by default, all token options can be configured at authentication.jwtOptions in the API configuration.
Queries
Queries to the Kano API are made to specific features services data which in turn query their specific underlying MongoDB collection. The way to query those collections is to use Feathers queries through REST URLs. In addition to those, we added in the KDK a few handy shortcuts to express commonly used queries. Here are some of the most useful query examples.
Request available stations
Typical use case is to display the stations on a map.
HTTP - GETRequest available observations
Typical use case is to retrieve the raw observations. You can filter spatially (i.e. bounding box) and temporally (i.e. time range) with most recent first.
HTTP - GETResult sample
{
"type": "FeatureCollection",
"features": [
{
"_id": "5f23ce6071b0b00008dff53f",
"type": "Feature",
"time": "2020-07-31T07:30:00.000Z",
"geometry": {
"type": "Point",
"coordinates": [
-0.12606156299146137,
45.02191991211479
]
},
"properties": {
"name": "L'Isle à Abzac",
"code_station": "#P726151001",
"H": 0.397
}
},
{
"_id": "5f23caea71b0b00008dfe457",
"type": "Feature",
"time": "2020-07-31T07:25:00.000Z",
"geometry": {
"type": "Point",
"coordinates": [
-0.12606156299146137,
45.02191991211479
]
},
"properties": {
"name": "L'Isle à Abzac",
"code_station": "#P726151001",
"H": 0.398
}
},
...
]
}Request observations at a station
Typical use case is to display a timeserie for the station.
HTTP - GETResult sample
{
"type": "FeatureCollection",
"features": [
{
"_id": {
"code_station": "#X331001001"
},
"time": {
"H": [
"2020-07-29T13:40:00.000Z",
"2020-07-29T13:45:00.000Z",
"2020-07-29T13:50:00.000Z",
...
],
"Q": [
"2020-07-29T13:40:00.000Z",
"2020-07-29T13:45:00.000Z",
"2020-07-29T13:50:00.000Z",
...
]
},
"type": "Feature",
"properties": {
"name": "La Durance à Cavaillon",
"code_station": "#X331001001",
"H": [
0.815,
0.815,
0.821,
...
],
"Q": [
36.87,
36.87,
37.458,
...
]
},
"geometry": {
"type": "Point",
"coordinates": [
5.032432216493836,
43.82748690979179
]
}
}
]
}Request latest observations at (a) station(s)
Typical use case is to retrieve most recent observations for the station, or display the observations on a map if not filtering by a station ID.
HTTP - GETResult sample
{
"type": "FeatureCollection",
"features": [
{
"_id": "64917e8ec06fb0000887fd3a",
"geometry": {
"coordinates": [
1.3351479476905552,
47.584957074484784
],
"type": "Point"
},
"properties": {
"H": -0.84,
"Q": 127,
"code_station": "#K447001001",
"name": "La Loire à Blois"
},
"time": {
"H": "2023-06-20T09:20:00.000Z",
"Q": "2023-06-20T09:20:00.000Z"
},
"type": "Feature"
}
]
}Use case example
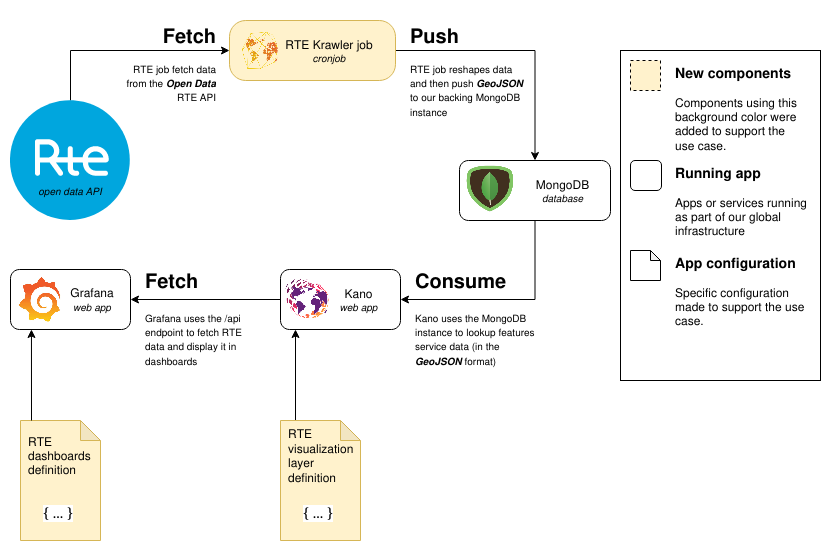
We used the Kano API to expose French nuclear power production data to a set of Grafana dashboards.
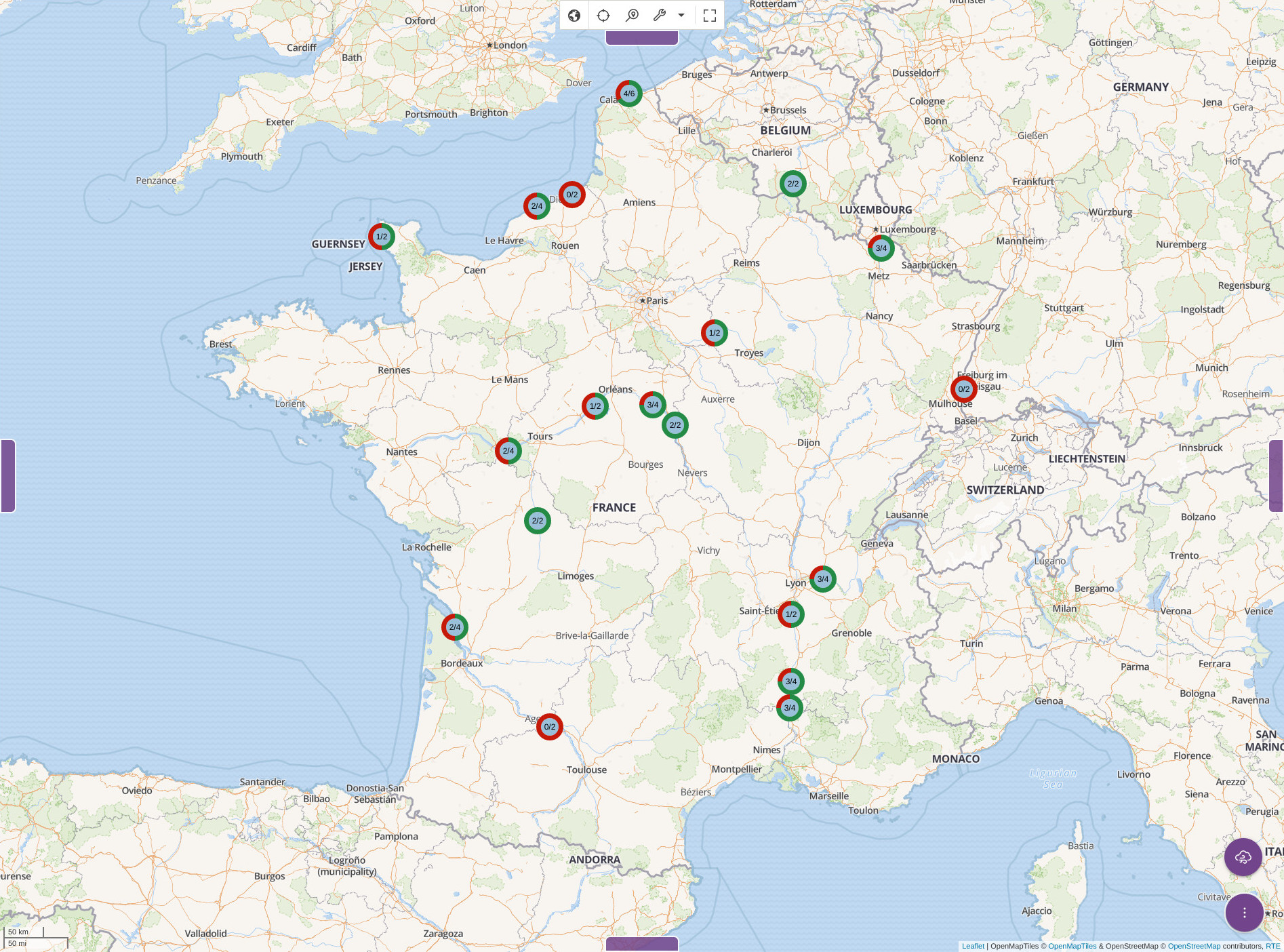
We first developed a Krawler job whose task is to scrap power production data and to push it into Kano's backing MongoDB database. On Kano's side, we added a layer declaring a feature service pointing on the database collections the Krawler job was populating. From that time, nuclear power production data was available for display in Kano. Here's what it looks like :
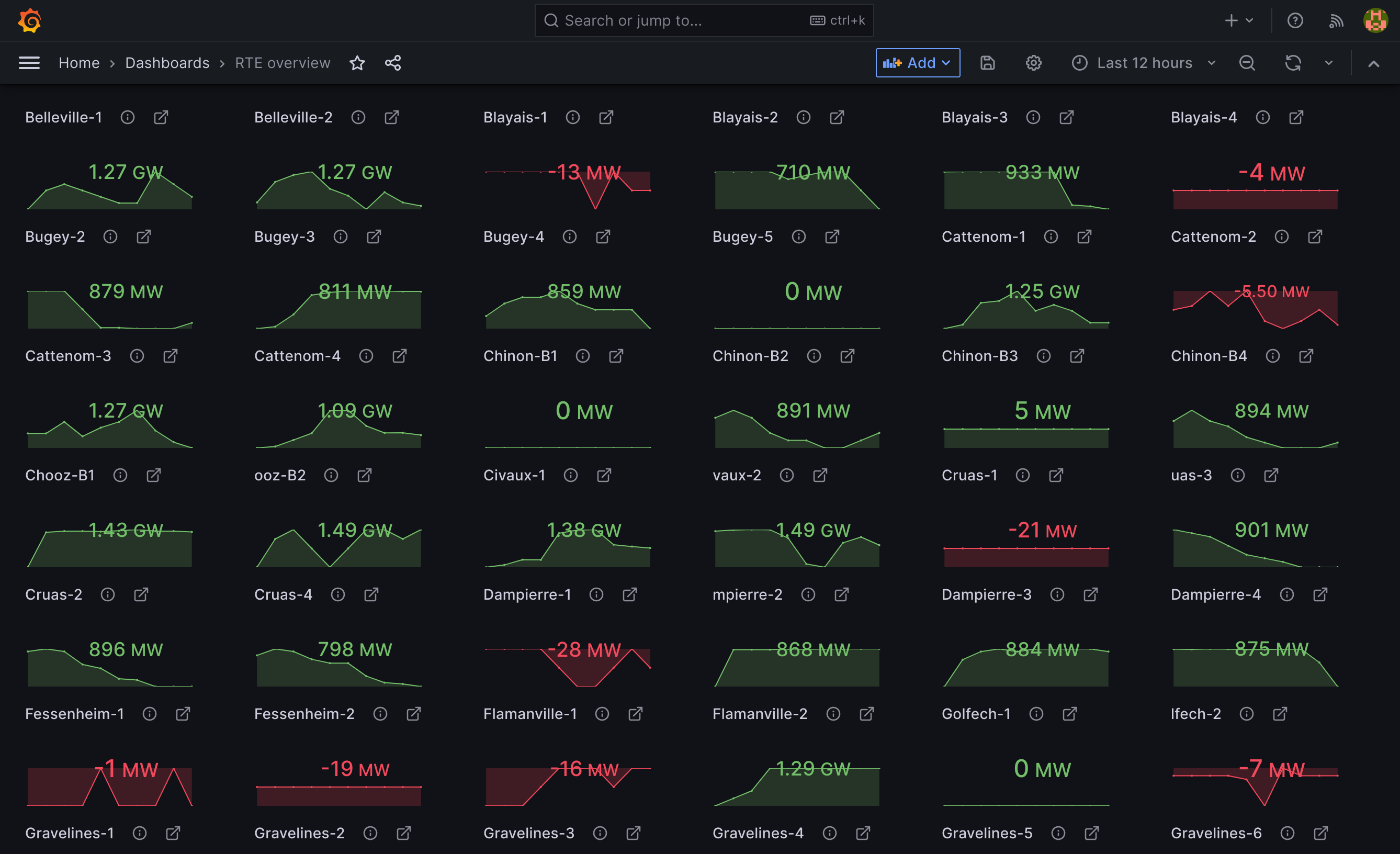
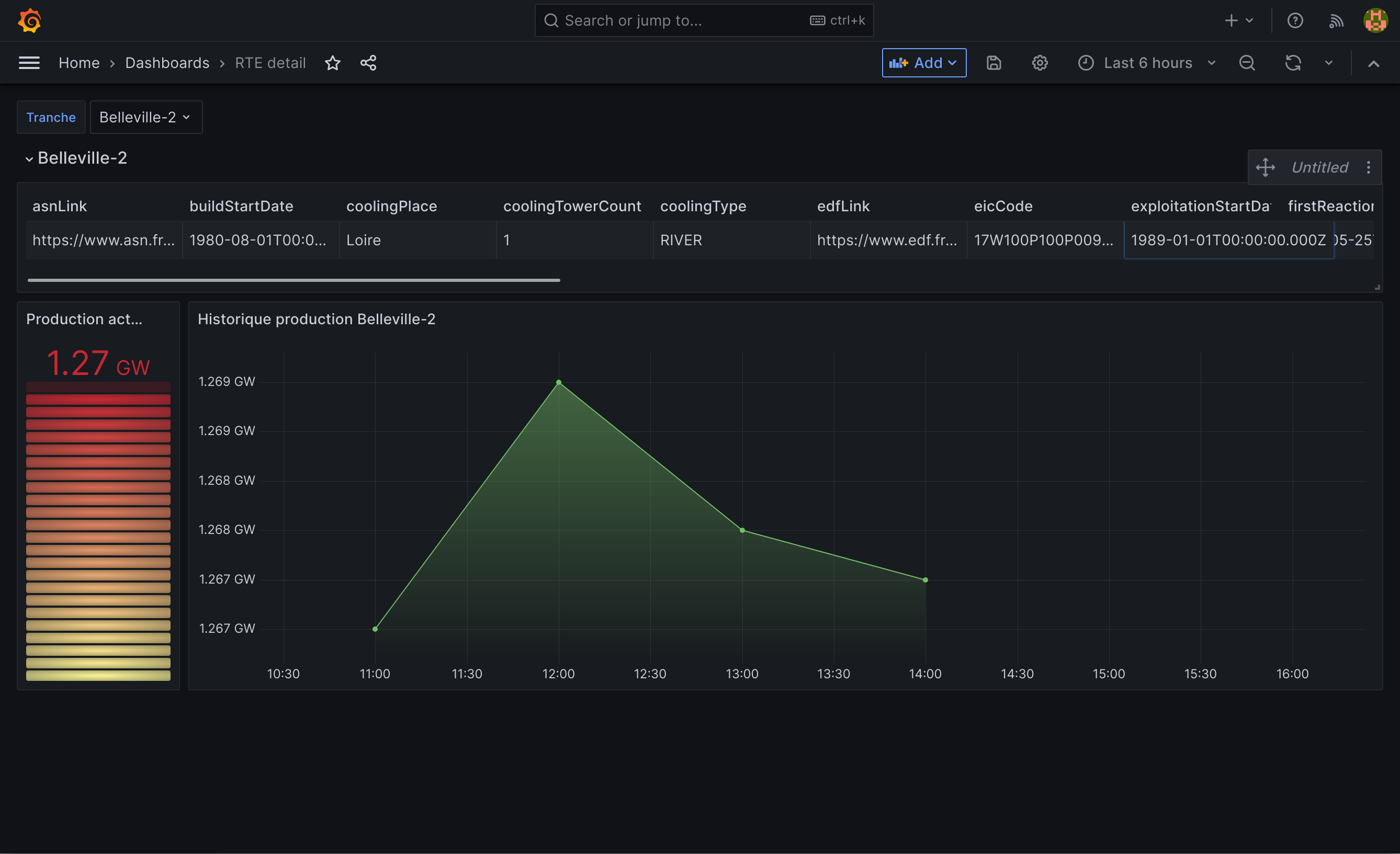
Once the collections started being populated, we looked for ways to connect Grafana to Kano's API endpoint. For this we used the Infinity Grafana datasource plugin allowing us to use it's JSON scrapping capabilities to feed Grafana. We created a JWT token for the datasource to be able to reach Kano's API. After creating dashboards and looking up some docs, we ended up with a set of synthetic dashboards:
Overall, here's the architecture of the whole solution :